Microservice Architecture - Part 2 (SSO, Logging, and all that) 17 Feb 2019
In part 1, we discussed how to compile and deploy the microservices. Remember that the microservices themselves are only a part of the microservice architecture. By its very nature, microservice architecture is distributed and that comes with a lot of benefits and some constraints. One of these constraints is that all the non-functional features such as security, logging, testability have to take distribution into account. Think of the microservice architecture as a city, where the microservice are people working in the city. In the city, you also need policemen, firefighters, teachers, healthcare providers to keep it up and running. The higher the number of people working in the private sector (a.k.a., microservices), the higher the need for non-operational people (a.k.a., utilities).
Compiling the UI
This sample microservice architecture does not focus much on the UI. It mainly serves the purpose of showing how to integrate it with the rest of the architecture. We will not dive into details. Sufficient to say, that the example was built with Angular 7.0 and the ngx-admin dashboard. In development, the UI is compiled by npm running on top of nodejs.
$ cd web-ui
$ node --version10.15.0
$ npm --version6.5.0
$ npm install... audited 31887 packages in 68.922s
$ npm run-script build
69% building modules 1280/1296 modules 16 active ...components\footer\footer.component.scssDEPRECATION WARNING on line 1, column 8 of
Including .css files with @import is non-standard behaviour which will be removed in future versions of LibSass.
Use a custom importer to maintain this behaviour. Check your implementations documentation on how to create a custom importer.
Date: 2019-02-21T09:13:40.912Z
Hash: e3a111b6560428e93784
Time: 76066ms
chunk {app-pages-pages-module} app-pages-pages-module.js, app-pages-pages-module.js.map (app-pages-pages-module) 3.16 MB [rendered]
chunk {main} main.js, main.js.map (main) 1.92 MB [initial] [rendered]
chunk {polyfills} polyfills.js, polyfills.js.map (polyfills) 492 kB [initial] [rendered]
chunk {runtime} runtime.js, runtime.js.map (runtime) 8.84 kB [entry] [rendered]
chunk {scripts} scripts.js, scripts.js.map (scripts) 1.32 MB [rendered]
chunk {styles} styles.js, styles.js.map (styles) 3.99 MB [initial] [rendered]
chunk {vendor} vendor.js, vendor.js.map (vendor) 7.17 MB [initial] [rendered]
Composing the microservices
At this point, we have all the necessary components. Let’s put everything together by starting the different Docker compositions. The order in which we start the compositions is important as there are dependencies:
docker-compose-microservices.ymlstarts the Kafka message broker and the microservices. We already tested this in part 1 to prove that all the microservices are available.docker-compose-log.ymlstarts an ElasticSearch, LogStash, and Kibana (ELK) suite alongside a Logspout companion container to take care of logs. This aggregates ALL logs from all containers and concentrate them into the ElasticSearch using Logstash. Kibana can then be used to analyze the logs and extract some intelligence, raise alerts and so on.docker-compose-api-gw.ymlstarts an api-gateway that routes the calls to the services and handle security by delegating authentication to an identity manager called keyloak. It also serves static content and as TLS termination.
$ cd docker-compose
$ docker-compose -f docker-compose-microservices.yml up &
$ docker-compose -f docker-compose-log.yml up &
$ docker-compose -f docker-compose-api-gw.yml up &
counterparty-service | 2019-03-12 20:06:27,203 INFO [stdout] (default task-1) counterpar0_.registrationStatus as registr16_0_,
counterparty-service | 2019-03-12 20:06:27,203 INFO [stdout] (default task-1) counterpar0_.status as status17_0_
counterparty-service | 2019-03-12 20:06:27,203 INFO [stdout] (default task-1) from
counterparty-service | 2019-03-12 20:06:27,205 INFO [stdout] (default task-1) Counterparty counterpar0_
kafka | [2019-03-12 20:10:15,744] INFO [GroupMetadataManager brokerId=1] Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager)
kafka | [2019-03-12 20:20:15,651] INFO [GroupMetadataManager brokerId=1] Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager)
kafka | [2019-03-12 20:30:15,652] INFO [GroupMetadataManager brokerId=1] Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager)
kafka | [2019-03-12 20:40:15,652] INFO [GroupMetadataManager brokerId=1] Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager)
kafka | [2019-03-12 20:50:15,654] INFO [GroupMetadataManager brokerId=1] Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.group.GroupMetadataManager)
...
kibana | {"type":"response","@timestamp":"2019-03-12T20:53:56Z","tags":[],"pid":1,"method":"get","statusCode":302,"req":{"url":"/","method":"get","headers":{"user-agent":"curl/7.29.0","host":"localhost:5601","accept":"*/*"},"remoteAddress":"127.0.0.1","userAgent":"127.0.0.1"},"res":{"statusCode":302,"responseTime":3,"contentLength":9},"message":"GET / 302 3ms - 9.0B"}
kibana | {"type":"response","@timestamp":"2019-03-12T20:54:01Z","tags":[],"pid":1,"method":"get","statusCode":302,"req":{"url":"/","method":"get","headers":{"user-agent":"curl/7.29.0","host":"localhost:5601","accept":"*/*"},"remoteAddress":"127.0.0.1","userAgent":"127.0.0.1"},"res":{"statusCode":302,"responseTime":8,"contentLength":9},"message":"GET / 302 8ms - 9.0B"}
....
api-gateway | 192.168.128.15 - - [12/Mar/2019:20:02:36 +0000] "POST /plugins HTTP/1.1" 409 213 "-" "curl/7.29.0"
api-gateway | 2019/03/12 20:02:36 [notice] 41#0: *139 [lua] init.lua:393: insert(): ERROR: duplicate key value violates unique constraint "plugins_cache_key_key" "
api-gateway | Key (cache_key)=(plugins:oidc::::) already exists., client: 192.168.128.15, server: kong_admin, request: "POST /plugins HTTP/1.1", host: "api-gateway:8001"
If everything went according to plan, you now have a working application ecosystem at https://localhost
Point your browser to https://localhost and you’ll get an nice UI.
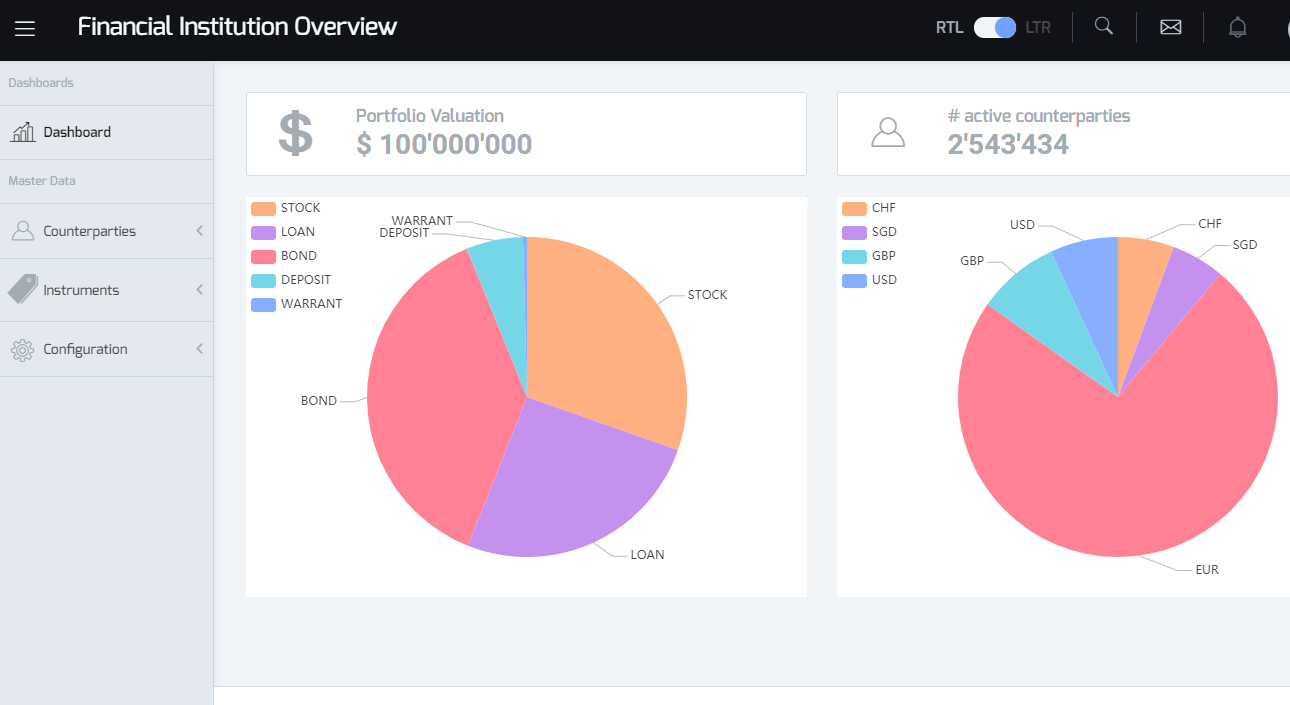
Angular 7.0 UI to the financial-app
By pointing it to the counterparty microservice at https://localhost/api/v1/counterparty, the API-gateway will detect that you are not authenticated and will redirect you
to the SSO platform to enter for credentials. Enter user1/user1
Keycloack SSO login form
Once authenticated you get redirected to the orginal URL you requested (https://localhost/api/v1/counterparty)

JSON result of the counterparty microservice that returns all counterparties.
Dissecting the docker-composes
As stated previously docker-compose composes several containers together to deliver a solution.
For instance, by starting the database first and then whatever service that requires a database.
Using docker-compose you set the same parameters, environment variables,
volumes that you would when starting a container with the command line.
From a general point of view, a docker-compose yaml file defines a series of services (e.g., database, microservice, web server) and then a series of “shared” services such as volumes, networks and so on.
Let’s take the example of the docker-compose-api-gw.yml file.
- First
version "2.1"defines the version of the syntax. Thenservicesdefines a section with a series of services. - In the below example, the first service is called
kong-databaseand is based on a postgres database version 10 as stated byimage: postgres:10. The name of the container (for instance what will appear if you rundocker ps) iskong-database. The hostname will also be calledkong-database. - What follows, is a section that describes the networks the container is participating into. This is very useful to isolate the containers from one another from a network perspective.
- The
environmentsection defines environment variables (similar to-ein the command line). - The healthcheck section defines rules to state whether or not a container is ready for prime time and heathly.
- The
kong-databaseexample does not expose ports but it could do so by defining aportssection that list the mapping of the ports of the container to the port of the host system.80:7070means the port7070of the container is mapped to the port80(http) of the host system. - Finally, the volumes section maps volumes from the host systems to the directory in the container. This is very useful to save the state of the container (e.g., database files) or to put custom configurations in place.
version: "2.1"
services:
kong-database:
image: postgres:10
container_name: kong-database
hostname: kong-database
networks:
- backend-network
environment:
POSTGRES_USER: kong
POSTGRES_PASSWORD: kong
POSTGRES_DB: kongdb
healthcheck:
test: ["CMD", "pg_isready", "-U", "kong", "-d", "kongdb"]
interval: 30s
timeout: 30s
retries: 3
volumes:
- pgdata-kong:/var/lib/postgresql/data
...After that very quick introduction to docker-compose let’s have a look at the services delivered by the three docker-compose files of the demo:
docker-compose-log.yml: Providing a logging infrastructure
Microservice architecture are distributed by nature and therefore cross-cutting concerns such as logging must take that aspect into account and aggregate the logs of the different containers. Without that it would be difficult to follow a user request that goes across many services to deliver the final value.
To implement it, we rely on the logspout log router. Logspout primarly captures all logs of all the running containers and route them to a log concentrator. Logspout in itself does not do anything with the logs, it just routes them to something. In our case, that something is Logstash.
Logstash is part of the ELK stack and is a pipeline that concentrates, aggregates, filters and stashes them in a database, usually elasticsearch.
Kibana depends on Elasticsearch and gets its configuration from a volumes shared from the host (./elk-pipeline/).
For more details about the Logstash configuration, please refer to ./elk-pipeline/logstash.conf.
Elastic Search stores, indexes and searches large amount of data. Like Logstash, it is distributed in nature.
Elasticsearch is starting first in docker-compose-log.yml because other services such as Logstash and Kibana depends on it.
Elasticsearch maps a host volume (esdata1) to its own data directory (/usr/share/elasticsearch/data). Thanks to that mapping, data are not lost when the container is stopped or if it crashes.
The final part of the puzzle is Kibana which visualizes the data stored in Elasticsearch to do business intelligence on the logs. This is very
useful to get a clear and real time status of the solution. Kibana depends on Elasticsearch and exposes its interface to the port 5601 of the host.
docker-compose-api-gw.yml : Prodiving api-gateway services
Microservice architecture are usually composed of a lot of services. Keeping track of these, providing and maintaining a clear API becomes very quickly challenging. Besides, the granularity of microservices often call for a composition to deliver actual value add. Besides, different applications might have different needs. For instance, a mobile app might need a different API than a web app. Furthermore, we often want to secure some services. For instance, using oauth2 protocol connected to an identity provider to offer Single Sign On (SSO) on the services.
In our case, the API gateway is called Kong and it requires a database. The docker-compose-api-gw.yml describes the following services:
kong-database which is a postgress database version 10 that holds the API gateway configuration
The api gateway itself api-gateway that is based on a docker image that we built previously unige/api-gateway when we ran mvn clean install -Ppackage-docker-image at the root of the project.
To get more details on how the image has been built, look at the Dockerfile in the api-gateway/src/main/docker directory. The image is based on kong:1.1rc1-centos but it is customized in several ways:
- There is an additional plugin to support openid
- A customized
docker-entrypoint.shto start Kong as root so that we can attach it to ports80and443that are privileged. - A customer
nginxtemplate to enable serving static content (the UI). - A shell script called
config-kong.shthat configures the API-gateway by defining the services and the routes to these services. By the way this file, is ran after the api-gateway is started and labelled as healthy by the container calledapi-gateway-init. The first line defines a service calledcounterparty-servicethat will route the request to the microservicehttp://counterparty-service:8080/counterparties. The servicercounterparty-serviceis the host name given by the microservice configuration. The second line creates a route in the API-gateway to the previous service. In that case/api/v1/counterparty, please note that the api-gateway can take care of versioning. Finally, the last line configures the OpenId plugin to provide authentication by telling the plugin to use theapi-gatewayclient of theapigwrealm of the keycloak.
#Creates the services.
curl -S -s -i -X POST --url http://api-gateway:8001/services --data "name=counterparty-service" --data "url=http://counterparty-service:8080/counterparties"
...
#Creates the routes
curl -S -s -i -X POST --url http://api-gateway:8001/services/counterparty-service/routes --data "paths[]=/api/v1/counterparty"
...
#Enable the Open ID Plugin
curl -S -s -i -X POST --url http://api-gateway:8001/plugins --data "name=oidc" --data "config.client_id=api-gateway" --data "config.client_secret=798751a9-d274-4335-abf6-80611cd19ba1" --data "config.discovery=https%3A%2F%2Flocalhost%2Fauth%2Frealms%2Fapigw%2F.well-known%2Fopenid-configuration"A database for Keycloak the SSO software called iam-db
The SSO service iam that is based on Keycloak v4.8.3. Please note that a complete configuration is loaded initially using master.realm.json. This configuration creates the required
realm, client and configuration to provide authentication to the api-gateway.
docker-compose-microservices.yml : Micro-services and message broker
Finally, the last of the composition are the microservices themselves. As you can see, most of the configuration is not required for the microservices themselves but for the infrastructure around it.
All the services belong to the backend-network nertwork.
First, it defines a ZooKeeper that provides distributed configuration management, naming and group services. Zookeeper maintains its state in two shared volumes that are respectively mapped
to the ./target/zk-single-kafka-single/zoo1/data and ./target/zk-single-kafka-single/zoo1/datalog directories of the host. Zookeeper is a mandatory component for the message broker.
Second, it defines a Kafka container. Kafka is a robust and fast message broker that excels at exchanging messages in a distributed way. It has a dependency to Zookeeper
and exposes its port 9092 to the same port on the host. It also saves its state on a mapped volume on the host.
Then, the counterparty service is a actual microservice (Finally !!!) that exposes its port 8080 to the port 10080 of the host. This microservice is based on Thorntail.
The instrument service is special as it connects to the message broker (Kafka) to send messages that will be read later on by the valuation service.
The other microservices : valuation-service and regulatory-service are more of the same.