Microservice Architecture - Part 3 (Diving into microservices) 04 Mar 2019
Introduction
In Part 1, we configured, compiled, and deployed microservices. In Part 2, we configured and deployed non-functional services such as security, and logging. In this chapter, we will dive into the concept of microservices. First, we will discuss why the community came with yet another architecture paradigm. Secondly, we will look at some definitions and the main properties of such an architecture. Then we will detail some of the technologies, microservice architecture leverage to deliver maximum value. After that, we will analyse the pros and cons of this architecture. Finally, we will discuss some of the architecture patterns related to microservices.
Why (yet) another architecture paradigm
The microservice architecture can be seen as a reaction to the monolith architecture. In particular, the fact that the bigger the application, the slower the pace of change. A monolith application is self-contained. Modules mostly communicate through method calls. While monolith do present some advantages in terms of performance (not scalability) and consistency for instance, they have a tendency to evolve to complex “thing” that run out of control. Modifying a monolith requires to rebuilt it completely and to ship it in one block. Furthermore, by its very nature, a monolith tend to favor API leaks and to decrease modularity. Finally, having one block means that scalability happens at that granularity which might lead to a waste of resources as all the modules will be scaled at the same time whereas not all the modules might need the same type of scalability or no scalability at all.
Following the model provided by M. L. ABBOTT and M.T. FISHER [1], scalability follows three dimensions:
- X-axis : horizontal duplication
- Y-axis : functional decomposition
- Z-axis : data partitioning
While X and Z scalability is feasible with a monolith, Y (functional) scalability is not. It is all or nothing.
The below figure presents a typical monolith architecture. Please note that,
- usually a monolith is implemented as a multi-tiers architecture
- monolith does not mean that it is not modular. It means that it is a “monolithic” unit of deployment. Everything is deployed together.
- cross-cutting concerns at shared and the monolith instance level
- inter service (modules) communication is usually method calls (vs inter process communication)
- scalability happens at the monolith level
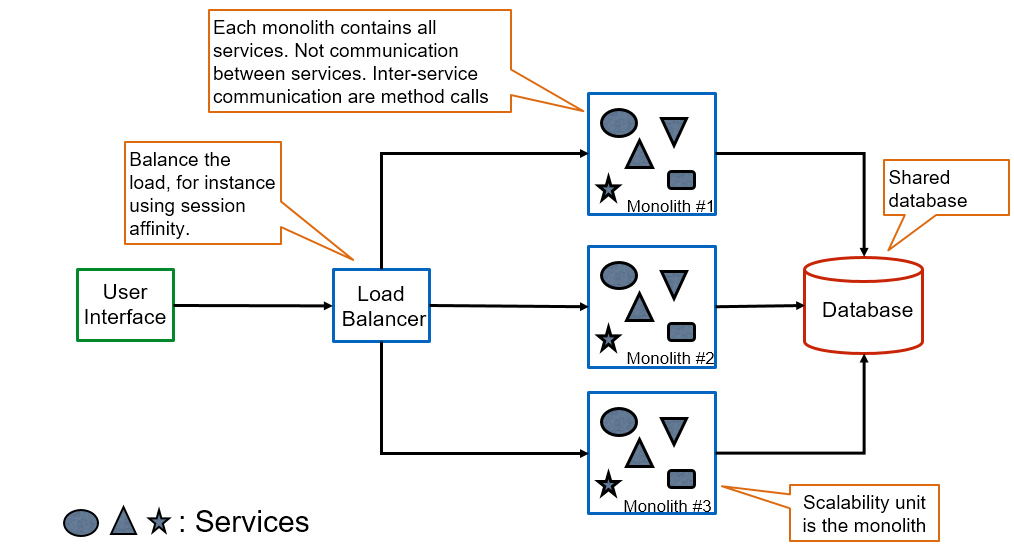
Monolith architecture
Breaking the monolith apart in small pieces, enables to make architectural decision at that level. For instance, to choose the most appropriate programming language or technology for each task. That being said adding heterogeneity and increasing the number of deployment units, comes at a price in terms of necessary infrastructure and thus complexity.
Definition(s)
At this core, microservice is an architecture (MSA) that is an evolution of the service oriented architecture (SOA). It inherits from SOA several key concepts. The most important one being that business added value is delivered by combining a collection loosely coupled services.
Reusing the definition of services from SOA, a service has the following properties:
- It logically represents a business activity with a specified outcome.
- It is self-contained.
- It is a black box for its consumers (and the communication between consumer and provider is formalized by a contract).
- It may consist of other underlying services.
These properties apply to microservices as well. The main difference between SOA and MSA is in the granularity of the services and some opinionated implementation choices. A key point to understand is that microservices have not been invented in isolation, they emerged alongside other game changers such as Agile, DevOps concepts, and Cloud computing.
Adding these influences to the mix, adds the following properties:
- each service is expected be elastic (horizontal scalability), resilient (failover), composible, minimum, and self-contained.
- each services must support automation, deployment, and testing as first class citizens.
- each is specialized in one thing and in doing that thing right
The term microservice has been coined around 2012 [2][3]. People trace it back to a workshop in Venice in 2011 but I was not able to find the proceedings.
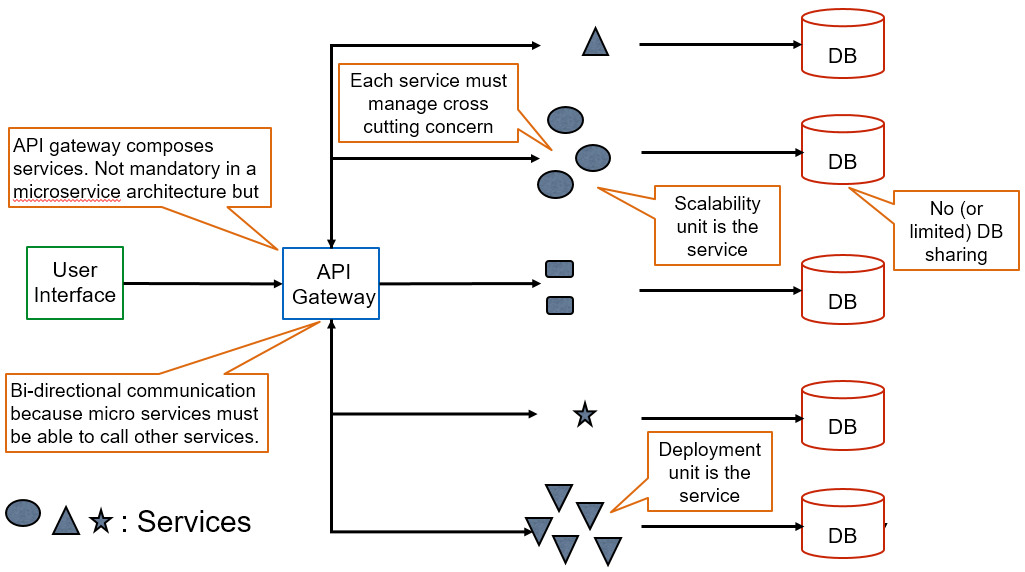
Microservice architecture
Technologies
Two main technologies are usually linked to microservices:
Cloud native technologies
Due to their distributed nature, Microservices call for a distributed way of deploying and management. Therefore, they are inherently linked to cloud native technologies such as containers and containers orchestration. As a matter of fact, without these technologies developing, building and deploying a microservice architecture would be so tedious and cumbersome that it would quickly collapse under its own weight.
Docker and Kubernetes bring the ease of deployment and management that is required to deal with hundreds of units. You can see as Kubernetes as the Operating System of the cloud and as Docker as the process of the cloud. Thanks to Docker, developer do not have to deal with OS/platform specific configurations. If it works in the container (mostly Linux) it will work in the cloud. Configuration can be scripted so the deployment is repeatable and automated. In association with Kubernetes, one can easily manages the elasticity, and health of the microservice ecosystem. Not to mention that a number of 3rd party tools are available as images that can be composed at will to provide crucial services such as logging, authentication, authorization, and monitoring.
Message broker
Another technology often associated with microservices is the message broker. Message Brokers are basically bus that can exchange messages at a very high speed in a distributed and elastic way. At the moment, Kafka is the most well-known of these. It is very often as a communication layer between the microservices. Kafka helps dealing with maintaining consistency by propagating messages in a asynchronous and transactional way. Message brokers are not a new concepts and they can be associated with the good old Enterprise Service Buses (ESB) of the Service Oriented Architecture era. The main difference is that, in order to avoid the ESB antipattern, message broker adopt a more lightweight approach. The big selling arguments around ESBs was that they would allow proper composition, discovery, and monitoring of the services as well as message and protocol transformation. The problem was that, at the end, all the business logic of the company was contained in the bus and thus it was extremely difficult to maintain. Microservices over Message Brokers take a more decentralized approach by letting the responsibility of the transformation, and composition to microservices.
Additional properties of microservices
Some of the properties of microservices are not inherited from the definition but rather from some implementation decisions. Please note that some of these properties might sound counter intuitive at first but they emerged to solve practical problems. Especially to limit service coupling.
Single Database per service
Sharing databases across multiple microservices increases coupling. Changing a database model for one service might impact other services. Furthermore, depending of the usage you might prefer a good old database or a key-value store. Having one database per service solves these problems at the expense of maintaining more technologies, instances and models.
Low cross-service reuse
This is, in my opinion, the most counter-intuitive thing. We have been told for years to reuse and to not duplicate code. And here it is, code duplications is promoted. More specifically the best practices is to not create “common” libraries. I would not be so “extreme” and simply say not to create common libraries with shared business code (for instance NO DTO).
One Domain per service
This is the most intuitive of the rules, restrict your micro services to deal with one and only one business domain. For instance, do not mix services for sales and for accounting. If within accounting, you have two accounting standards, then let’s have two services.
Service Granularity
Choosing the right granularity for your services is more an art than a science. There are numerous articles out there to help you choose the right granularity [4] [5]. Finding the right level of granularity is usually a tradeoff between thus between maintainability and scalability on one hand, and deployment complexity and performance on the other hand. It is always a choice between maintainability at the micro level (the service) and the macro level (the whole ecosystem).
Although it is difficult to predict the actual penalty of microservices on the performance as it depends of the use case, [5] predicts a 10% penalty per hops (microservice to microservice communication) on the total roundtrip.
I like the breakfast example where a single macro service called prepare breakfast ends up being 3, 12, or 60 services depending of the level
of granularity. Now imagine, we need to scale the 60 services to have … say 3 instances. All of a sudden you have 180 instances to maintain and to manage. This is becoming exponentially more complex.
In that example, the right level is probably 12 as it proposes some valuable reuse and still limit the complexity.
That being said, nothing stops you to have different level of granularity per domain depending of the expected evolutivity, reuse, and performance. As a rule it is better to start with coarser services and to go granular on a case by case basis.
There are recommendations out there that a microservice should between 50 to 500 lines of codes. This is, in my opinion, the worst possible metric out there. It is way too dependent of the language and technology.
The most important rule about the granularity is to respect the service boundaries:
- It doesn’t share database tables with another service.
- It has a minimal amount of business entities,
- It is stateless (and if stateful it is on purpose).
- It does take data (un)availability into accounts. For instance by implementing local caches for non-managed entities.
- It is the single source of truth for the business entities it manages.
Architecture patterns
Command Query Responsibility Segregation (CQRS)
Command Query Responsability Segregation is all about … guess what … reducing coupling. The idea is to have a different API for querying data and for creating/updating them. At its core, it seggregates the model and the storage to query data from the model and storage that keeps the single version of truth of a particular business entity. The two APIs can be part of the same microservice or in two different microservices. One use case to have it on two separate microservices is to be able to scale out querying (or vice versa).
As each microservice can have its own store, then you could imagine using Cassandra (which is known to be very efficient in writing) for persisting and Elasticseach for read (which is known to be very efficient in reading). Command and Query Responsibility Segregation (CQRS) was first introduced by Greg Young [6] and is itself an evolution of the Command Query Separation (CQS) by Bertrand Meyer [7]
In the sample architecture, the instrument service has one view of the instrument model but the valuation service as another one. To be fully CQRS compliant, the instrument service should have
had a different model to persist and to query. As JPA does not support two entities on the same database object, we would have to use a constructs like JPA queries and select new to support a
different model for persistence and for reading. For more information on how to use the select new``, please refer to this article
and this article.
CQRS is very associated with Event sourcing (see below).
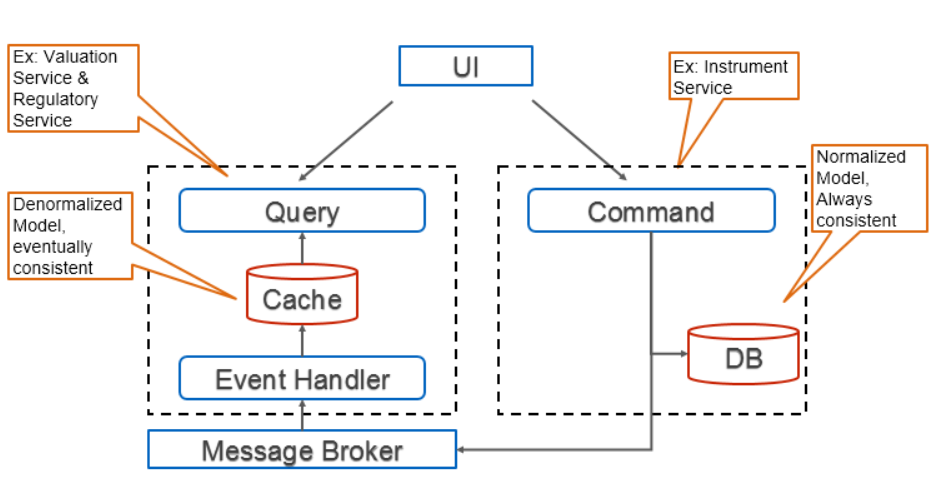
CQRS + Event Sourcing architecture
Event sourcing & Message Bus
In an architecture where neither the data store nor the data model is supposed to be shared, keeping the consistency between the different stakeholders is challenging. Having distributed transactions that span across multiple services is difficult to implement and even more difficult to maintain. That is why, instead of looking for consistency at any point in time, we are looking at eventual consistency. Of course, eventual consistency might be a problem in some use cases and that must be assessed on a case by case basis.
The fundamental concept behind Event Sourcing is that All changes to an application state are stored as a sequence of events [8]. In other terms, changing the value of a given field for a given entity is stored as a message.
Ultimately, you can reconstruct the current state by replaying all the messages starting with the initial state.
In the sample architecture (see below), the instrument service is writing any changes to a message broker that is distributed to all microservices that need it. In this case, to the valuation service and to the regulatory reporting service. Instrument service has the single version of the truth and all other service will eventually be consistent. Of course, internally the instrument service must guarantee that updating its own store and the bus is made transactionally.
Since the changes are stored in the bus, they can be replayed. For instance, when a new instance of a service joins so that it can update its internal state.
API Composition / API Gateway
As we already discussed, non-functional concerns such as load-balancing, versioning, security (authentication, authorization, TLS termination) must be managed at the microservice level.
Furthermore, maximizing microservice reusability implies granular services. The client could easily compose the microservices but this means a high coupling between the client and the services as well as a lot of traffic between the client and the microservices.
One way of mitigating this, is to add an API gateway in front of the microservices to avoid direct coupling between the client and the individual services. Besides, it will handle composition locally in the application network. Finally, it will apply cross-cutting concerns uniformally on all the requests.
The sample application relies on an application gateway to deliver authentication, versioning and TLS termination (see figure below)
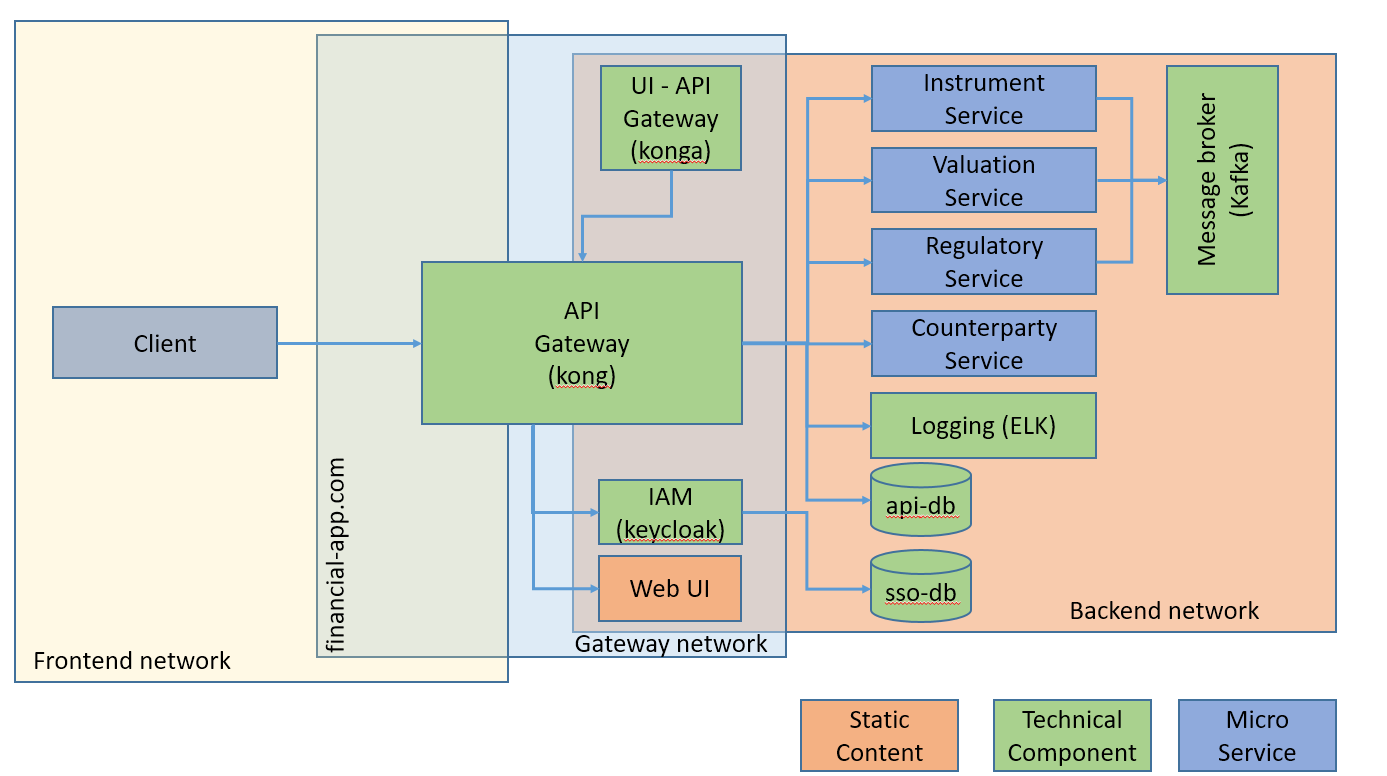
Network topology and high level component view of the micro-service architecture
Pros and Cons
Let’s reflect on the pros and cons of the microservice architecture. Like any architecture, it is a tradeoff between a set of non-functional requirements.
Pros
Fist the positive aspects
Scalability,
Scalability (both horizontal and vertical) can happen a very granular level. Therefore, no resources are wasted on scaling components that do not require it (like it would be the case for a monolith). Furthermore, because it is easy to segregate stateful from stateless components, scalability happens most of the time on pure stateless microservices. In a monolith, one stateful component forces the whole monolith scalability to take stafulness into account.
Failover, Fault Tolerance, High-Availability
In a very similar way to scalability, Failover, Fault Tolerance, and High-Availability can be targeted to the components that require it. Similarly, statefulness can be limited to the few services that require it (if any).
Time to market, Adaptability
Because the services are small and loosely coupled, they can be changed and deployed with limited risk of regression to other services. This increases time to market and is a big step forward continuous delivery.
Team Independence
Similarly to the time to market, the loose couple implies low inter-team dependency. That being said, this is sort of by product to the microservice architecture. A modular monolith should in theory achieve the same level of loose coupling. The problem is that when calls internal (rather than through the network), developer have a higher tendency to break module boundaries thus increasing the coupling.
Technology Adaptability
Again, loose coupling and low dependency enact new practices such as deciding which technology to choose on the case by case basis. That being said, depending of your organization, this can be more of a curse than a blessing. You can very quickly end up with exotic technologies and languages that only the microservice creator knows.
Reusability
Thanks to the granularity, services are much more dedicated to a particular task. This is favoring reusability by composition.
Cons
Like any architecture, there is no free lunch:
Increased resource consumption
As a microservice architecture entails many more instances (e.g., VMs, JVMs) to run that its monolithic counterpart. Furthermore, entities are very often replicated between the instances (to increase loose coupling). All of that lead to higher overall resources (memory and CPU) consumption. This is compensated by the fact that more resources are available than years ago before the cloud era.
Operational Overhead / Deployment complexity
The profusion of services and their associated dependencies (DB, message broker, …) can very quickly lead to an operational nightmare. The operation team needs to master the concepts and the related tools for monitoring the ecosystem (Docker, Kubernetes, ELK, …). This has a cost, both in terms of skills and manpower.
Cross-Cutting concerns
Since the cross-cutting concerns are managed at the service level, it can significantly complexify deployment : a microservice might be straightforward but let’s add it authentication, authorization, logging, versioning, failover, balancing and it is a completely different story. Doing system testing on such environments can be very challenging.
Architecture Complexity : Distributed system
Microservices are distributed by nature and thus exposes developers to “The 8 fallacies of distributed computing” :
- The network is reliable.
- Latency is zero.
- Bandwidth is infinite.
- The network is secure.
- Topology doesn’t change.
- There is one administrator.
- Transport cost is zero.
- The network is homogeneous.
When designing your microservice architecture, you will have to think of all of the above. Another interesting law to remember is the [9] :
Fowler’s first law of distributed computing : don’t distribute your objects
While Fowler’s rightfully insists in a this post that there is a huge difference between distributing objects and (micro) services. Therefore, he underlines that his 2004 comment is not in any way applicable to microservice architecture. Although I agree that the two are very different, I think that it is interesting to look at his entire chapter that is available online. Before laying down the law, Fowler spend some time explaining how he came to that conclusion. Most of the argument is that not choosing the granularity of the interfaces (API) will lead to poor performance and will massively increase complexity. This is also very true for microservices.
While there are architecture patterns and tools to deal with them, it just means extra-complexity and therefore you should ask yourself where it does and where it does not make sense.
Eventual consistency
Hereafter a summary of the main “pros” and “cons”. Please note that this is not an absolute evaluation. The weight that you should put in each of these is highly dependent of your use-case and context. For instance, team independence is not a real concern in a small startup with 5 employees. On the other end, operation complexity tends to be less of a problem if you already have skilled devops teams.
| Property | Microservice | Monolith |
|---|---|---|
| Scalability | + | - |
| Release/Updatability, Time to marker | + | - |
| Failover, Fault Tolerance, High Availability | + | - |
| Team Independence | + | - |
| Technology Adaptability | + | - |
| Reusability | + | - |
| Resources Consumption (like for like for a given throuput/volume) | - | + |
| Operational Overhead | - | + |
| Cross-Cutting Concerns (Security, Logging, Caching, Auditing, Configuration, …) | - | + |
| Architecture complexity (Distribution, Consistency, Governance, Integration testing, …) | - | + |
Closing Thoughts
To sum it up : whereas microservice architecture is a powerful tool in your toolbox, it is in no way a silver bullet. Microservice architecture is very adapted when a high level of elasticity is required but it comes at a price in terms of complexity of operations. Architecture is always a tradeoff between non-functional requirements and therefore the first thing to do is to establish these NFRs. If scalability and updatability is not an issue then having a modular monolith is probably more appropriate. Furthermore, there is nothing stopping you to adopt a hybrid approach by starting to break a monolith in coarse services and to refine it as needed.
Bibliography
- [1] Martin L. Abbott and Michael T. Fisher. 2009. The Art of Scalability: Scalable Web Architecture, Processes, and Organizations for the Modern Enterprise (1st ed.). Addison-Wesley Professional.
- [2] James Lewis. 2013. Micro services - Java, the Unix Way. 33rd Degree Conference, Krakow Poland. http://2012.33degree.org/talk/show/67
- [3] Fred George. 2013. MicroService Architecture, https://www.slideshare.net/fredgeorge/micro-service-architecure
- [4] Chistian Verstraete, 2017, https://cloudsourceblog.com/2017/01/03/cooking-breakfast-and-microservice-granularity/
- [5] Shadija, D., Rezai, M., & Hill, R. (2017). Microservices: Granularity vs. Performance. In UCC 2017 Companion - Companion Proceedings of the 10th International Conference on Utility and Cloud Computing (pp. 215-220). Association for Computing Machinery, Inc. https://doi.org/10.1145/3147234.3148093
- [6] Greg Young, 2010. CQRS Documents. https://cqrs.files.wordpress.com/2010/11/cqrs_documents.pdf
- [7] Bertrand Meyer. 1988. Object-Oriented Software Construction (1st ed.). Prentice-Hall, Inc., Upper Saddle River, NJ, USA.
- [8] Martin Fowler, 2005, Event Sourcing : https://martinfowler.com/eaaDev/EventSourcing.html
- [9] Martin Fowler. 2002. Patterns of Enterprise Application Architecture. Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA.